Speeding up HashSet, HashMap and loops in Dart
If you have been profiling your application, you have probably experienced a mixture of frustration and excitement when looking at a particularly “fat” method in the CPU Flame Chart. Frustration — because your program is still not perfect in terms of speed. Excitement — that you can get to the cause of the problem and squeeze some more free time for the processor for more useful calculations. At least, I regularly fall victim to both of these feelings, to which this article owes its appearance.
My case is an attempt to squeeze more speed and features out of the Flame game engine than it can “out of the box”. Game development has its own peculiarities in comparison with “parsing large JSON” or eliminating the glitch when playing an animation once. At least because potentially voluminous calculations are performed on absolutely every frame in games. So, my experience probably won’t resonate much with the problems most Flutter developers encounter.
However, I would like to note that the approaches described here can work not only for Dart, but for any language, especially high-level ones — you just need to specify the details of how certain data structures are implemented in your language, and based on this choose the optimal method of working with them.
Visualize the problem
So, let’s say you opened Flame Chart and saw some huge forEach, inefficient HashSet and HashMap:



Note that these functions are mostly the last in the call stack. That is, slow operation is not caused by some custom logic inside the loop, but by the very number of these loops.
Of course, when the engine’s “internals” and private methods of built-in data structures come to the fore, the first step is to see if we can somehow reduce the number of loops. Here the decision depends on your particular case. The trouble is that it may not solve the problem, and filling an array with a lot of elements and then repeatedly looping through them may be simply necessary for the logic of your application. As, for example, in a game engine — there it is simply impossible to throw some game objects out of processing for a long time without creating noticeable bugs.
And now it’s the end of everything? Are we going to fork Dart and rewrite its “slow libraries”? Or should we throw away this language altogether and start rewriting the whole program in another “trendy modern and exactly the fastest language in the world”? No. Instead, I suggest that you just do a little work with your head, especially since some of the solutions are right on the surface, but because of their triviality they may simply go unnoticed.
Deceptive Iterable
High-level languages are great. They take care of a lot of minor headaches, allowing you to concentrate on the main things. But if you have to do deep optimization, you will have to give up some of these conveniences.
Take Iterable, for example. It is the same for List, Map, and Set, but only at the interface level. And the implementations are not identical at all. So, if you have a set of data inside a HashSet or HashMap, and you have to loop over it many times, it’s worth making one extra pass to save this data into a regular List. Iterating over a simple list will be the cheapest. And yes, it would be better to make this list unmodifiable (List.filled(emptyObject, growable: false)), and add items to it by rewriting indexes in the for loop — in case the code for filling the list is also in the performance-critical zone.
Here’s an illustrative example from the bowels of Dart sources. Compare the work of a regular list iterator and HashSet:

You can verufy it personally here and here.
In an ordinary list iterator moves over a single list, which is expected, but inside a HashSet there are many lists on which the iterator jumps according to some logic. The kind of logic is not important for now, but the fact that this logic is more than just index increment — this is most important.
A similar picture will be shown in case of a battle between access by key for HashSet and access by index for List. The latter obviously will produce the result faster.
How to use List instead of Map.
Attention! Too obvious things described here!!!
Look at data that stored in your Map. What is its lifecycle? At what point do you know exact number of items in collection? When do you fill out the collection and when do you check the result? Because the process can be significantly accelerated if:
- You know collection length before using it or filling with data.
- You can store data in simple indexed lists, which are unmodifiable while you working with them.
- Your code requires a lot of Map access operations. That calls should take significant space in Flame Chart. Otherwise, there are no point in optimization, because it will produce additional loop over Map’s elements that will make your code even slower.
If everything fits together, then you can do optimization steps:
- Collect Map “keys” into unmodifiable List<T>
- Create another unmodifiable List<T> to store your Map’s values. Both arrays length must be equal.
- Then access both arrays just by index, as long as both of them stay unmodified. This should be much faster than access by key for Map data structure.
The description is very abstract just because real-life cases could be very different and I do not know exactly, which one you have. Next, I’ll try to show an example of code, but it still is too abstract and does not have any sense itself.
Benchmark’s results look very predictable:
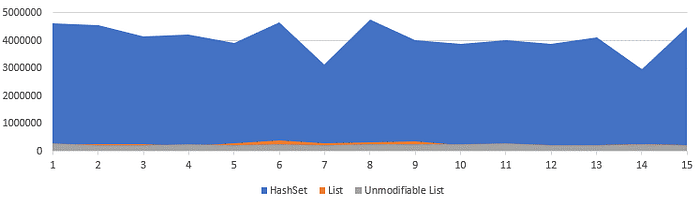
It seems that for the sake of a 15-fold increase, it is worth both bothering and rolling back from a complex data structure to a simple one, from “sexy iterators” to the grandfather’s “for(i=0….”
Accelerating Set and Map without giving them up
But what if the conditions of the task do not allow you to roll back to the lists? Even in this case, we still have the opportunity to increase performance.
It’s all about hash functions. Set and Map uses hashCode, the field which exists in every Dart object. But the trick is same as with iterators: only interface is similar, but realizations are different. If we would make googling again, we will find out that there are several bug-reports to dart developers about significant difference between hash algorithms of different data types. For example, here you can see a commit that enhances hashCode function for integer data type: https://github.com/dart-lang/sdk/commit/8c0df46887744e229b74bfb8c6bfc05df67f67eb . But there is still an open discussion that Object.hashCode could work faster (but this is not accurate): https://github.com/dart-lang/sdk/issues/24206
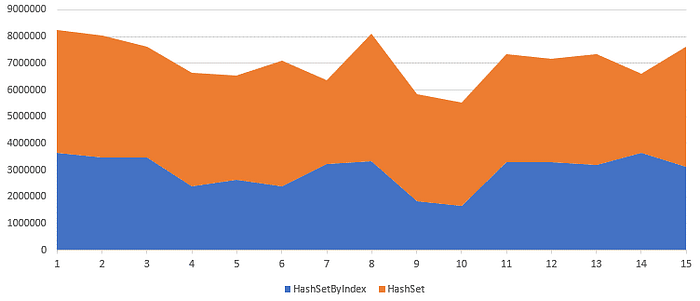
From what we have read, a simple conclusion suggests itself: if we cannot identify an object in the collection simply by its ordinal number, then at least we will try to identify it simply by some unique integer identifier. What will happen? Let’s look at next benchmark:
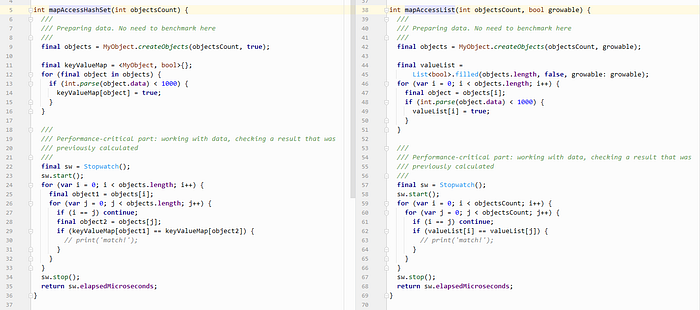
Also, here is a fragment of more optimal code:
int mapAccessHashSetByIndex(int objectsCount) {
final objects = MyObject.createObjects(objectsCount, true);
final keyValueMap = <int, bool>{}; // <--- Key is integer, not object!!!
for (var i = 0; i < objects.length; i++) {
final object = objects[i];
if (int.parse(object.data) < 1000) {
keyValueMap[i] = true;
}
}
///
/// Performance-critical part: working with data, checking a result that was
/// previously calculated
///
final sw = Stopwatch();
sw.start();
for (var i = 0; i < objects.length; i++) {
for (var j = 0; j < objects.length; j++) {
if (i == j) continue;
if (keyValueMap[i] == keyValueMap[j]) { // <-- access by int index, not object itself!
// any useful logic here
}
}
}
sw.stop();
return sw.elapsedMicroseconds;
}Well, it is not 15 times faster, just 2 times. Still a good result, still worth it to mess around a little!
When every microsecond matters
Imagine, you can’t to rewrite your code by described recipes, but still want to improve performance. Will you have any choice between approaches? Yes, you will! But from this point you will need data structures of special kind, bitwise operations magic, and also you will struggle with probability of inaccurate results.
Let’s see a simplest case:
- You have pairs of objects.
- You need to save and access data foreach pair relation
If you won’t think a lot about the task, you will simply create Map<Object, Map<Object, ObjectData>> data structure and work with this heavy and slow monster. But it will solve your task anyway.
In some cases, you can to rewrite this to lists as I described previously. But if you can’t, there are another solution: store your data in structure like Map<int, Data>. The key of map is integer and you can obtain it using bitwise AND operation, for example: final key = a.hashCode & b.hashCode.
However, this magic is not too black, this is simplest level of arcane. If we will dig deeper, we will find more advanced data structures for more specific cases.
Let’s look at two of them: BloomFilter and XorFilter. These structures allow to check, if a set of objects do NOT contain specified object. Or to check, if a set of objects DO contain specified object with high probability (but with some probability of false-positive result). These structures claim to work faster than Hash Sets, but are slower while filling with data.
In the repository https://github.com/FastFilter/ you can find a lot of implementations for wide variety of languages… except Dart. I’d like to use XorFilter in my own application, because it claims to be faster than BloomFilter, but there is no any existing library for Dart. But for Bloom Filter there are two implementations. I chose this one for my experiments: https://pub.dev/packages/dart_bloom_filter
I going to show another portion of benchmarks but before let me do some important notices:
- In these cases, performance changes are very… tiny. So, if you have another ineffective code in performance-critical part, this tiny optimization will be useless
- For the same reason, on small amounts of data / numbers of runs / debug modes, the difference may be at the level of computational error.
Actually, when running the benchmark on 10,000 elements in VM mode, I got identical performance for both the HashSet and the BloomFilter. But having compiled the application for Windows and increased the number of elements and iterations to 10,000,000, the difference immediately became visible:
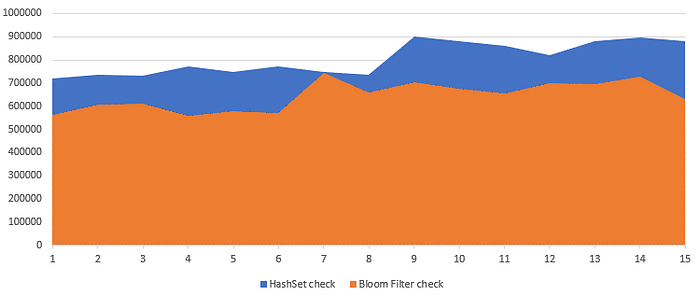
Well, we squeezed out a little more… 20% faster than the already fast one… whether it’s worth it for your task, taking into account the side effect — the probability of a false positive test result — is up to you to decide. But it’s good that there is some possibility at all.
Below I posted HashSet and BloomFilter benchmark implementations.
HashSet:
int hashSetCheck(int elementsCount) {
///
/// Preparing data. No need to benchmark here
///
final objects = MyObject.createObjects(elementsCount, false);
final random = Random();
final objectsSet = <int>{};
for (var i = 0; i < objects.length; i++) {
if (random.nextBool()) {
objectsSet.add(i);
}
}
///
/// Performance-critical part: working with data, checking a result that was
/// previously calculated
///
final sw = Stopwatch();
sw.start();
for (var i = 0; i < objects.length; i++) {
if (objectsSet.contains(i)) {
// do something
}
}
sw.stop();
return sw.elapsedMicroseconds;
}BloomFilter:
int bloomCheck(int elementsCount) {
///
/// Preparing data. No need to benchmark here
///
final objects = MyObject.createObjects(elementsCount, false);
final random = Random();
final bloomTrue = BloomFilter<int>(objects.length, 0.1);
for (var i = 0; i < objects.length; i++) {
if (random.nextBool()) {
bloomTrue.add(item: i);
}
}
///
/// Performance-critical part: working with data, checking a result that was
/// previously calculated
///
final sw = Stopwatch();
sw.start();
for (var i = 0; i < objects.length; i++) {
if (bloomTrue.contains(item: i)) {
// do something
}
}
sw.stop();
return sw.elapsedMicroseconds;
}I rewrote my code following the article’s recommendations, but it didn’t get any faster!
And yes, I will not mislead you: if you rewrite a couple of loops to a more optimal algorithm, it may not affect the speed of your application at all. Or it may affect it somehow. It depends on how often this code block is used and what other performance-affecting methods there are around it.
In my case, there were at least eight rewriting and re-profiling cycles, although I didn’t count them on purpose. Each change itself did not increase the perceived speed of the application, but it removed a block with “long” code from the Flame Chart, or significantly reduced it.
In the end, the effect became noticeable only when all the optimizations started working together. Namely the effect was expressed in the fact that instead of 28 FPS my game engine demo began to produce stable 60, processing collisions simultaneously for 161 moving objects. In Flame Chart it looks like this:

Yes, BloomFilter is quite small, but it still glows. Although HashSet.[] was glowing even more. Otherwise, there are no more “particularly long” cycles, as it was on the screens at the beginning of the article, which, in general, can be considered a success.
Why not use Isolates?
Some people may ask, why bother with performance in a single thread, if theoretically it is possible to spread computations across different isolates? But sadly, Dart has big problems here:
- Copying a large amount of data between isolates per frame is 100% too expensive, and shared memory is not available to us (in fact, we have a workaround with ffi, C++ and integer representation of a pointer to shared memory area — for native. But this is too tricky and in fact requires to use other language a lot. And in pure JS we can use SharedArrayBuffer, but this solution also does not cross-platform and requires separate implementation).
- Well, to speed-up communication between isolates we can to convert our data into binary format. We even have great library to make it faster in runtime and save our own time: FlatBuffers library https://github.com/google/flatbuffers. But with a large number of objects, it is still too expensive to serialize into binary form. The lack of support for launching some necessary libraries inside isolates, the presence of callbacks in class variables, the need to rewrite everything separately in order to be able to launch an isolate on the web — all this makes the task extremely spicy, complex, tricky and unpredictable.
But I have implemented this part in my project, it works successfully and gives a visible performance gain. But was it easy, fast and simple? No. - Your code becomes asynchronous, although for the game engine logic to work correctly, it is simply necessary that some calculations finish before the next one starts.
- As a result, we come to a situation when code execution from the previous frame overlaps with the code from the next frame, and the heavier the calculations are, the more layers of such “overlapping” we get.
- As a result, more resources are spent not even on your code itself, but on maintaining async-await, and you will have fast-executing functions on dart and veeery looong-running code of native libraries of the platform in your Flame Chart.
In summary, it is more reliable and easier to optimize work in one thread than to spread it over several threads. That’s how it is, our praised Dart, what can you do about it… But the issue of parsing large JSON has been considered up and down 😊
Useful links
You can find complete benchmarks code in the repository and poke around yourself: https://github.com/ASGAlex/dart_iterables_benchmarks
Important note: it is better to run each test separately, because if you just run the functions sequentially within one application, you don’t know at what moment Garbage Collector will come and ruin all your measurements by cleaning up the memory after the previous test.
If anyone is interested in poking what kind of game engine I have, please visit the source code at https://github.com/ASGAlex/flame_spatial_grid and the demo on the web: https://asgalex.github.io/flame_spatial_grid/ .
In the article I mentioned using flat buffers to speed up communication with the isolate and running isolates on the web via web-workers. In general, this is an extensive topic, so I won’t dive into it here, but if anyone is interested in seeing examples of use, please do:
- Schemas for flat buffers and generated code with some manual additions.
- Data convertation into binary buffer, sending to isolate (in 4 parallel threads), getting results in binary format with decoding “under the hood” into readable format.
- Isolate itself, adapted for work in the web.
I hope, one day I will be able to tell you a success-story about truly parallel computations in Dart, or at least a partial-success story… 😊
